
近日,王田教授团队博士生李雨婷关于联邦半监督学习中的模型泛化与个性化平衡方面的研究工作被CCF A 类国际会议 IEEE 41st International Conference on Data Engineering (ICDE 2025) 录用。该工作第一作者为2024级博士研究生李雨婷,指导老师为王田教授,合作者为北京师范大学王文华博士。
Yuting Li, Wenhua Wang, and Tian Wang*, pFSSL-D: Generalization Meets Personalization in Dual-Phase Federated Semi-Supervised Learning, in 2025 IEEE 41th International Conference on Data Engineering (ICDE).
会议简介
ICDE(International Conference on Data Engineering)是数据库与数据挖掘领域的顶级国际会议,与SIGMOD、VLDB并称为数据库领域三大顶会,被中国计算机学会(CCF)列为推荐A类国际学术会议。ICDE 2025将于2025年5月19日至23日在中国香港举行。
研究背景和动机
边缘设备在算力和存储上的发展为模型训练创造了巨大潜力。然而,数据隐私与安全问题的日益凸显严重制约了这些优势的发挥。联邦学习(Federated Learning,FL)作为解决这一困境的去中心化范式,使多个参与方能够在不共享原始数据的前提下共同训练模型。然而当前大多数FL算法基于有监督学习框架,即假设各终端设备数据均带有标注。但分布式环境中普遍存在标注稀缺现象,因为人工标注不仅需要专业知识,还面临高昂的人力成本。
为应对FL中的标注数据短缺问题,联邦半监督学习(Federated Semi-Supervised Learning,FSSL)日益受到关注。FSSL通过融合联邦学习与半监督学习技术,旨在利用大量分布式未标注数据缓解标注稀缺问题。但现有FSSL方法还面临以下挑战:
1、 集中式预热瓶颈:主流FSSL方案依赖中心服务器提供的标注数据进行模型初始化(图1(a)),在边缘设备通信受限、网络不稳定的场景下,标注数据不足会导致预热阶段失效,系统性能断崖式下降。
2、 数据异构衍生的挑战:FL固有的non-IID特性会引发全局模型在本地客户端的性能退化。虽然在传统联邦学习中可通过个性化微调缓解,但FSSL场景下这一过程面临标签缺失效应和小数据过拟合陷阱。针对标签缺失问题直接在客户端应用半监督学习方法会导致全局模型与本地数据分布的失配从而降低伪标签质量,放大训练噪声,阻碍本地更新。此外,有限的本地数据会加剧过拟合风险,可能导致预训练阶段获得的泛化能力发生灾难性遗忘。
针对上述挑战,本文提出一种两阶段联邦半监督学习算法 pFSSL-D(图1(b))。算法创新地采用去中心化warm-up机制和自适应参数解耦联邦微调策略,有效平衡全局泛化能力与客户端个性化需求,并确保异构环境下的鲁棒性。
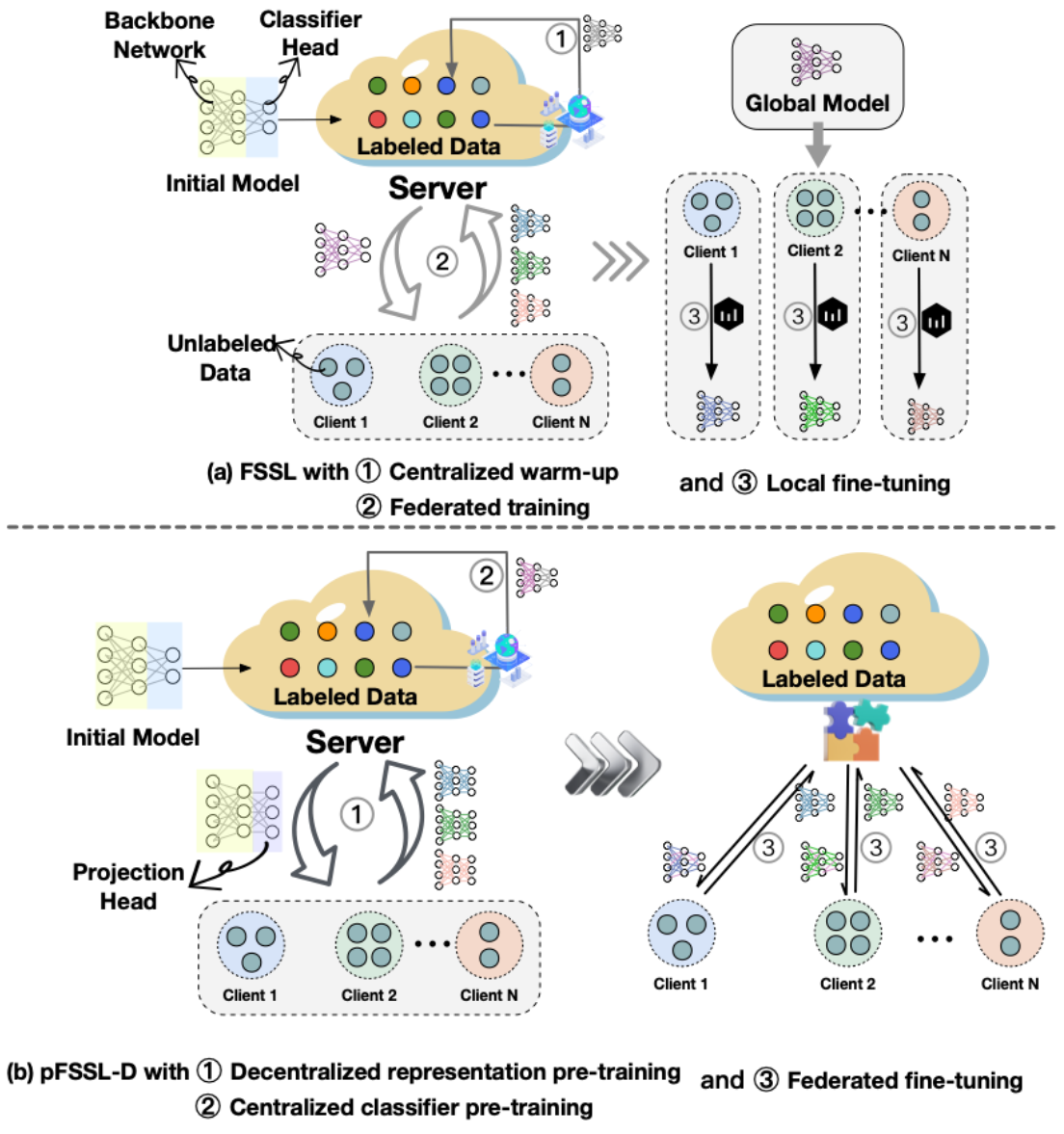
图1 传统FSSL方案与pFSSL-D框架对比
解决方案
针对集中式预热的瓶颈问题,本方案在第一阶段中通过特征对齐与对比学习相结合的方式,构建具有强迁移能力的特征提取模型。然后基于预训练的主干网络,利用服务器端有限的标注数据对分类头进行微调。该方法在保证通信效率的前提下,显著提升了预训练模型的泛化能力和分类精度。第一阶段方案流程如图2所示。
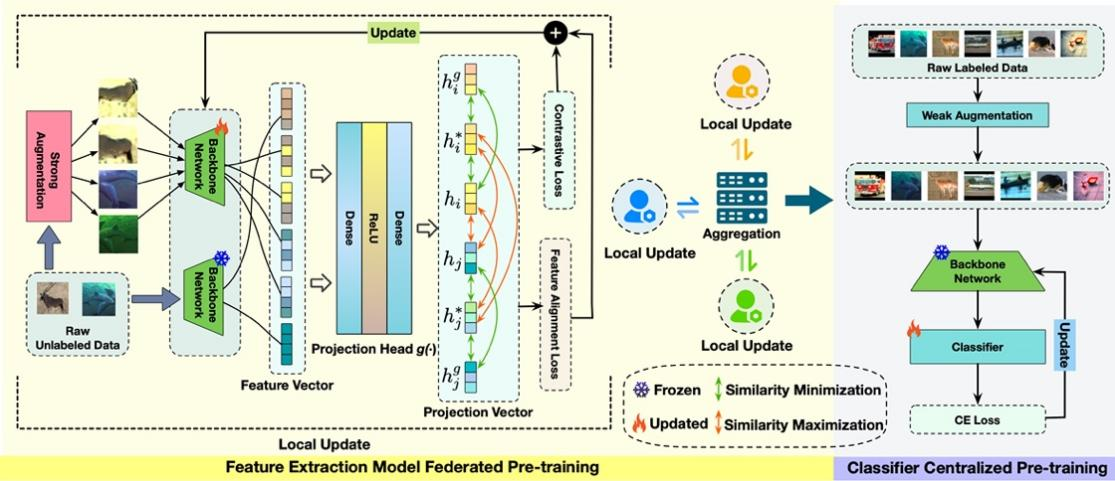
图2 联邦预训练阶段工作流
针对数据异构衍生的挑战,本方案在第二阶段提出一种语义信息引导的Mixup数据增强策略SimMix,既能扩充数据集又可抑制噪声。同时创新性地设计了参数级别的联邦微调方法,将模型参数解耦为泛化子集和个性化子集,为每类参数制定差异化的更新策略从而显著提升模型的异构数据分布适应性。第二阶段方案流程如图3所示。
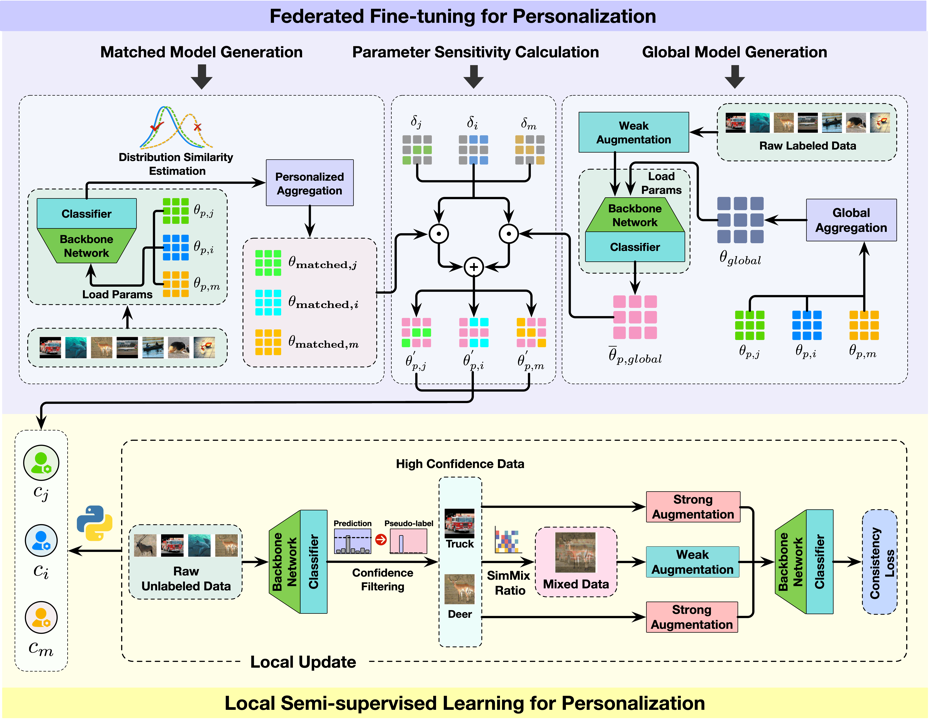
图3 联邦微调阶段工作流
实验评估
我们在5种数据集上进行了大量的实验,包括SVHN,FMNIST,CIFAR-10,Fed-ISIC2019以及ImageNet-Tiny。我们将pFSSL-D与多种方案进行性能对比,验证了所提出方案的高效性。
表1 不同方案在不同数据分布下性能对比
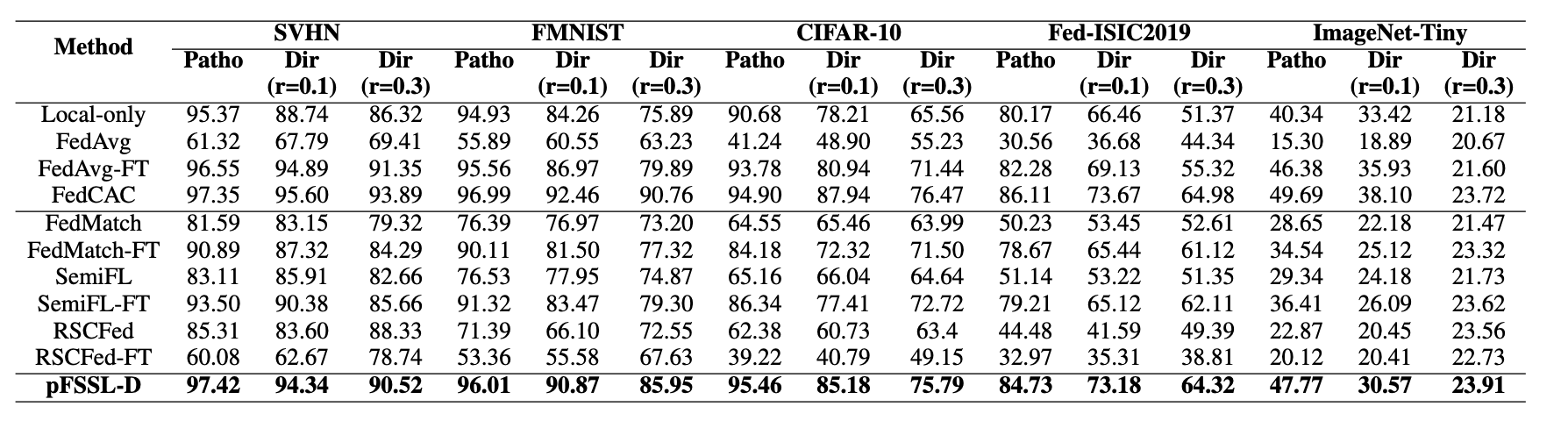
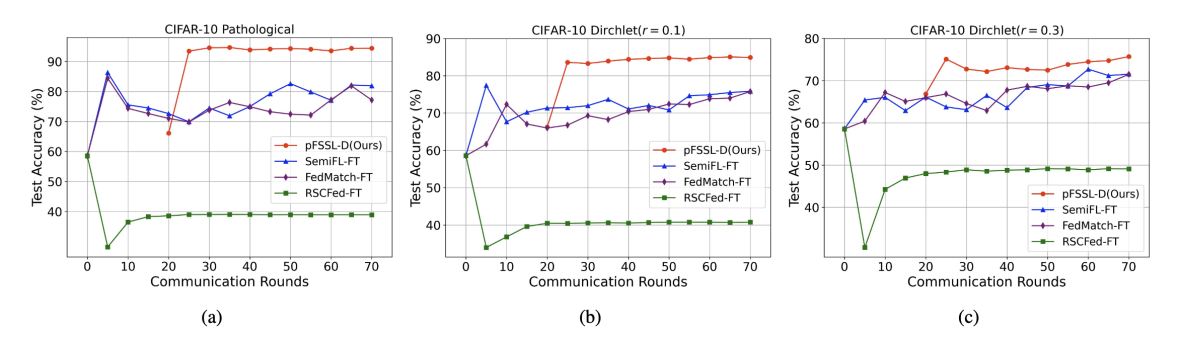
图4 不同方案的收敛速度对比
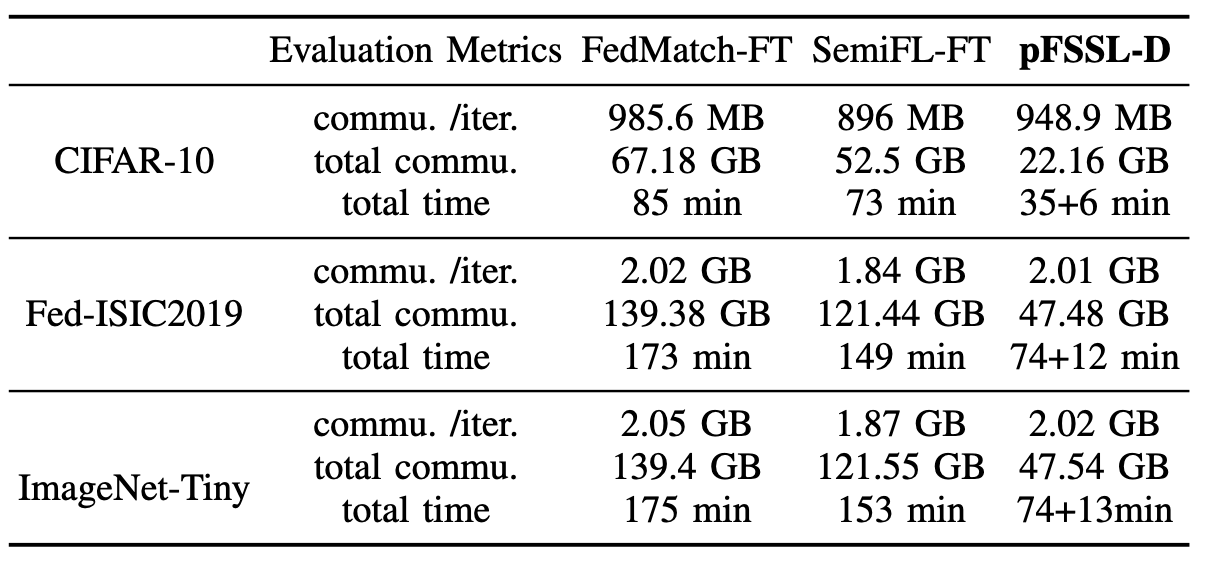
表2 不同方案的资源消耗量对比
总结
本文提出了一种面向联邦半监督学习的双阶段框架,旨在通过生成个性化模型解决数据异构性和标签稀缺性带来的挑战。在第一阶段,我们采用具有特征对齐的分布式对比学习方法,在保证通信开销的同时,高效预训练出具备强鲁棒性和泛化能力的特征提取模型。第二阶段通过区分泛化参数与个性化参数来优化模型更新策略,从而同步提升全局模型的鲁棒性和客户端的个性化性能。实验表明,pFSSL-D在保证精度的同时具有更快的收敛速度,优化了系统可扩展性和客户端模型性能,展现出优异的实际应用潜力。
