
近日,AI与未来网络研究团队在云边协作大语言模型服务的工作Enhancing LLM QoS through Cloud-Edge Collaboration: A Diffusion-based Multi-Agent Reinforcement Learning Approach被计算机领域顶级国际期刊IEEE Transactions on Services Computing(以下简称TSC)录用。

图1 论文首页截图
向量数据库LLM应用优势2025.04大语言模型(LLMs)作为生成式AI领域的代表性技术,虽然展现出卓越的性能,但其庞大的计算需求和云端依赖特性导致了显著的服务延迟和网络传输压力。边缘计算通过云边协同架构有效降低了服务延迟并节省了网络带宽,然而现有优化方法(如模型剪枝、量化等)需要对LLM进行侵入式修改,限制了方案的通用性。相比之下,向量数据库提供了一种非侵入式的优化方案,通过缓存历史问答数据来减少LLM推理计算或完善上下文理解,这种边缘部署方式能够为用户提供低延迟、高质量的服务体验。
实际系统中进行LLM请求调度面临着两个关键性挑战:一方面,LLM请求具有高度多样性特征,需要建立高效的特征提取和相似性分析机制来支持调度决策,传统方法难以适应这种动态需求;另一方面,现有决策算法(如强化学习)存在样本效率低和策略更新灵活性不足的问题。实际部署中,离散请求特征提取和相似性分析更为复杂,训练数据不足与动作探索易导致算法收敛困难,进而影响请求完成质量。
AI与未来网络研究院的这项工作针对边缘计算环境中大语言模型服务中的关键挑战,提出了一种基于扩散模型的LLM请求调度算法。在每个边缘服务器部署强化学习智能体,通过特征提取网络学习请求特征,并基于向量检索结果与请求特征的深度分析来实现LLM请求的智能调度。同时,为解决实际系统数据采集困难和LLM请求离散性的问题,采用了基于专家演示的网络训练方法,有效克服了训练初期向量数据丰富度不足和智能体动作采样导致的模型拟合难题。
为增强边缘计算场景中的LLM服务质量,本研究提出了一个向量数据库辅助的云边协同LLM服务质量优化框架(图2)。该框架将向量数据库部署在边缘服务器用于缓存LLM请求处理结果,提出“基于扩散模型的多智能体强化学习方法”且能够有效应用于真实系统中。本研究设计了一个具有高度通用性的解决方案,提出的框架无需对LLM结构进行修改即可适配于各种主流模型,包括Qwen,ChatGPT和DeepSeek模型等。
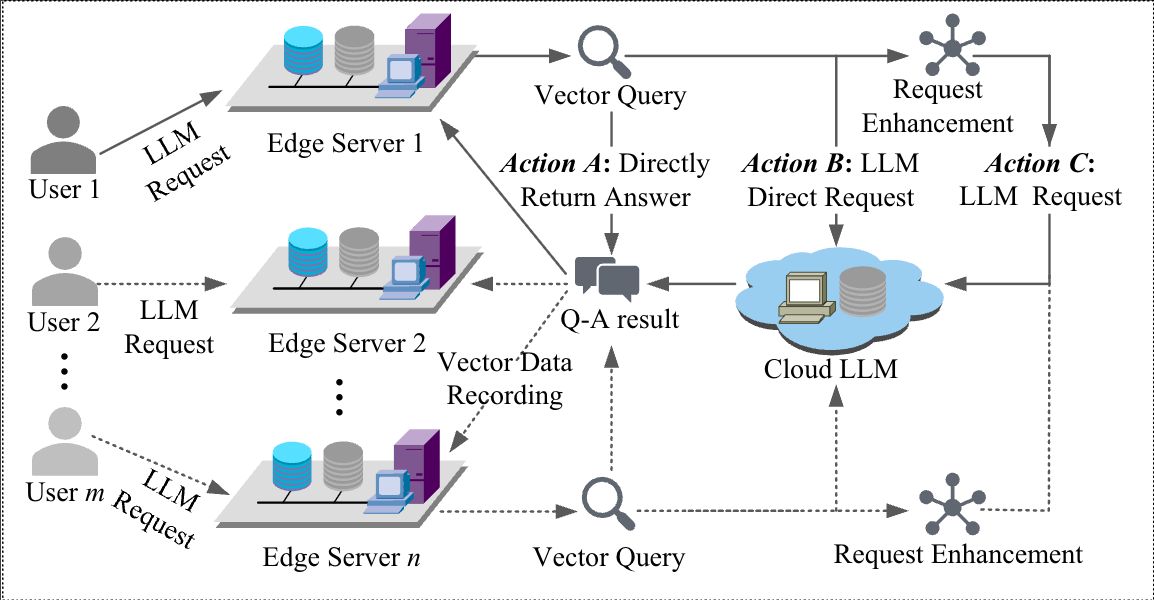
图2 VELO框架主要包含以下三种请求调度动作:(1)向量数据库中缓存了与请求高度相似的请求时,直接从向量数据库返回答案;(2)向量数据内容与请求无关时,直接请求云LLM并返回答案;(3)当向量数据库内容和请求存在一定的相关性时,通过向量数据检索结果增强请求后请求LLM。
TSC是IEEE服务计算领域顶级期刊,属于CCF(中国计算机学会)推荐的A类国际学术期刊,是涵盖服务计算领域中的顶级刊物,主要发表服务计算、软件工程、系统软件领域的最新研究进展。本项工作的第一作者为AI与未来网络研究院2023级博士研究生姚智,指导老师为贾维嘉教授和唐志清老师。合作者包含北京师范大学AI与未来网络研究院杨文冕老师。本研究得到国家自然科学基金(编号62272050、62302048)、广东省教育厅人工智能与多模态数据处理重点实验室、北京师范大学珠海校区人工智能与未来网络研究院、广东省人工智能与未来教育工程技术研究中心、珠海市科技创新局(编号2320004002772)、北京师范大学珠海校区交叉智能超算中心等项目资助。
